


 Openshift-Beratung
Openshift-Beratung
 Open Source Monitoring
Open Source Monitoring
 Integration-Testing
Integration-Testing


Observability - damit businesskritische Anwendungen gesund bleiben
Ihre Applikationen generieren eine Vielzahl an Messungen & Analysen. Dieser Datenflut gilt es Herr zu werden, wenn Sie sicherstellen wollen, dass Ihre businesskritischen Anwendungen gesund bleiben. ConSol setzt auf Observability – Beobachtbarkeit. Wir überwachen Ihre IT-Anwendungen ganzheitlich und schützen Sie vor unliebsamen Ausfällen, die Sie Zeit & Geld kosten und schlimmstenfalls Ihre Reputation schädigen. Mit Open Source Observability unterstützen wir Sie bei Konzeption, Tool-Auswahl, Implementierung und Anbindung von Tracing, Log Aggregration, Error Management und weiteren Observability-Disziplinen.
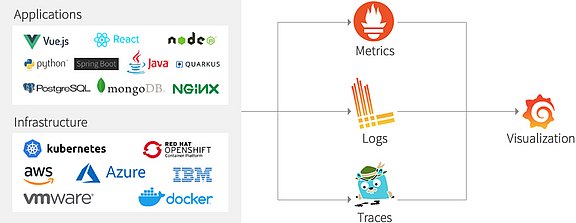
Sämtliche Applikationen und die darunter liegende Infrastruktur produzieren Metriken, Logs und, wo sinnvoll, auch Traces. Diese werden von bewährten Open Source Tools wie Prometheus (Metriken), Loki (Logs) oder Jaeger (Traces) gesammelt und aufbereitet. Anschließend werden diese Daten zentral in Grafana-Dashboards visualisiert. An dieser Stelle erhält der Nutzer einen Überblick über für ihn freigegebene Applikationen und Infrastruktur-Komponenten. Zur Langzeitspeicherung der Daten können zusätzlich Datenbanken wie InfluxDB zum Einsatz kommen.
Observability – Auf der Jagd nach „Mister X“
Observability setzt sich im Wesentlichen aus drei Bausteinen zusammen: Monitoring, Logging und Tracing. Das Monitoring gibt uns Auskunft, wenn ein definiertes Service Level oder Qualitätskriterium unterschritten wird. Die Anwendungsentwickler definieren hierfür entsprechende Metriken, welche wiederum direkt aus der Applikation heraus bereitgestellt werden. In den Logs finden wir die Fehlermeldungen der einzelnen Softwarekomponenten. Sie zeigen, an welcher Stelle in den jeweiligen Services der Fehler auftritt. Den Weg, den ein Aufruf zwischen den Services zurückgelegt hat, bevor er zu einem Problem geführt hat, können wir im Tracing nachvollziehen. All diese Informationen können wir mittels Korrelations-IDs gemeinsam in einem zentralen Dashboard betrachten. So bewahren wir auch in komplexen Anwendungen den Überblick und spüren die Fehlerquelle schnell auf.
Mehr als
200 Kund*innen
vertrauen ConSol
in Sachen
IT & Software
Observability Tools
Die von uns favorisierten Applikationen für Observability sind überwiegend Open-Source-Lösungen. Gegenüber kommerziellen Lösungen gibt es hier keinerlei Nachteil. Wir haben sie seit etlichen Jahren sowohl bei unseren Kunden als auch bei uns selbst im produktiven Einsatz. Ihr Funktionsumfang ist beachtlich.

Prometheus ist der De-facto-Standard für Cloud-native Monitoring und Alerting. Es bietet eine einfache Konfiguration, wo und wie Metriken gesammelt werden können. Die meisten Anwendungen unterstützen den Export von Metriken nach Prometheus. Und auch für selbst geschriebene Applikationen gibt es für alle gängigen Programmiersprachen und Frameworks sehr gute Unterstützung des Exports von Metriken nach Prometheus.

Mit Loki können Logs einfach importiert und indiziert werden. Die Konfiguration ist an die von Prometheus angelehnt. Das Ziel ist es, schnell Logs für bestimmte Kriterien zu finden. Daher darf nur ein sehr kleiner Index geschrieben werden. Durch starkes Parallelisieren von Auswertungen können Abfragen selbst bei großen Datenmengen schnell ausgeführt werden.

Grafana wird für das Visualisieren von Metriken verwendet. Es bietet eine sehr gute Integration von Prometheus, Loki und Jaeger. Hiermit lassen sich in Graphen neben Metriken auch Traces anzeigen. Es ist außerdem möglich zu einzelnen Traces zu springen und für bestimmte Metriken auch Logs zu diesen Metriken zu zeigen. Neben einer großen Auswahl an vordefinierten Dashboards mit verschiedenen Metriken kann der Benutzer auch selbst Dashboards erstellen.

Jaeger unterstützt den OpenTracing-Standard. Hierdurch ist eine einfache Integration von Applikationen in Jaeger möglich. Für selbst geschriebene Applikationen gibt es, ähnlich wie bei Prometheus, eine breite Unterstützung von Programmiersprachen und Frameworks. Weitere Vorteile von Jaeger, neben der großen Verbreitung, sind die einfache Installation und Skalierung selbst bei großen Datenmengen.

ElasticSearch (und sein OpenSource-Fork OpenSearch) kommen in einer Vielzahl unserer Log Aggregations und Tracing-Systeme zum Einsatz. Die vielfältigen Möglichkeiten des Betriebs, der Steuerung des Datenflusses, der Hochverfügbarkeit und der Datensicherung machen es in vielen Umgebungen zur richtigen Lösung. Wir unterstützen bei Systemplanung, Setup, Konfiguration und Anbindung.

Das VictoriaMetrics-Framework ist eine effiziente Alternative zu Prometheus für komplexere Infrastrukturen, die sowohl kostenlos als auch als Enterprise-Lösung mit fortgeschrittenen Features (z.B. Anomaly Detection via AI-Technologie) verfügbar ist.
Webcast-Aufzeichnung: Effektive Observability
Die enorme Zunahme von Microservices erzeugt eine regelrechte Datenflut. Aus diesen Datenmengen gewinnbringende Informationen zu ziehen ist, besonders mit veralteten Tools, eine Herausforderung und Mammutaufgabe.
Der Webcast gibt einen Überblick über effektive Observability für moderne Cloud Workloads.
Speaker: Christoph Ehlers, Leiter Software Engineering bei ConSol und Iliya Iliev, Senior DevOps Engineer, ebenfalls bei ConSol
Observability: Wichtige Begriffe & Erläuterungen
Logging wird genutzt, um spezielle Events oder problematische und fehlerhafte Situationen zu protokollieren, so dass bei Schwierigkeiten die Fehlerkonstellation nachvollzogen werden kann. Es liegt in der Verantwortung der Entwickler, wie aussagekräftig diese sind. Es gibt für die meisten Programmiersprachen Logging-Frameworks, die für standardisierte Log-Formate sorgen. Dies ist dann wichtig, wenn Logs zentral gesammelt werden und nach bestimmten Kriterien wieder gefunden werden sollen. Insbesondere in den flüchtigen Containern ist es zwingend notwendig die Logs zentral zu sammeln. Denn lokale Log-Files gehen mit Restart des Containers verloren.
In heutigen verteilten Systemen und insbesondere in Microservice-Architekturen reicht das einfache Logging nicht mehr aus. Hier muss der Ablauf über verschiedene Services oder Methoden hinweg nachverfolgbar sein, da häufig gerade das Zusammenspiel zwischen Microservices zu Problemen oder Performance-Bottlenecks führt. Dazu ist es erforderlich, dass neben den End-User-Aufrufen noch zusätzliche Information über die Service-Aufrufe weitergegeben und in speziellen Tracing-Log-Events hinterlegt wird. Darüber hinaus müssen diese Tracing-Logs auch für alle beteiligten Services zentral gespeichert werden, damit die Aufrufhierarchien dargestellt werden können. Bei Verwendung von externen Bibliotheken oder Services stellt dies zusätzliche Anforderungen an diese.
Über OpenTracing stehen Frameworks für viele Programmiersprachen zur Verfügung, die über sogenannte Spans oder Korrelations-IDs die End-User-Aufrufe über die verschiedenen Services hinweg einfach zuweisbar machen. Dieser Standard wird schon von vielen Open Source-Libraries unterstützt.
Metriken sind numerische Repräsentationen von Zuständen (z.B. Anzahl von offenen Connections) oder Durchsätzen (z.B. Schreibvolumen auf einer Festplatte seit einem bestimmten Zeitpunkt, Aufruf einer bestimmten Funktionalität). Sie unterscheiden sich damit von Logs und Tracing-Daten, die sich auf einzelne Events beziehen.
Metriken können über sogenannte Exporter oder Metrik-Endpunkte zu Standardapplikationen (z.B. NGINX, DBs oder Objekten in Kubernetes) abgefragt werden. Die kundenspezifischen Applikationen sollten so instrumentiert werden, dass man damit die SLAs messen lassen und weitere Information über die Nutzung (z.B. Anzahl und Antwortzeiten von kritischen Aufrufen) für detaillierte Performance-Betrachtungen gewinnen kann.
Das aktuell verbreitete Metrikformat wurde von Prometheus eingeführt und über OpenMetrics standardisiert. Metrikpunkte setzen sich dabei wie folgt zusammen:
- Metrikname: beschreibt, was repräsentiert wird. Z.B. server_open_connection_count
- Labels: anhand von Labeln kann man verschieden vermessene Instanzen unterscheiden. z.B. Instance=127.0.0.1:8080.
- Zeitstempel: zu welchem Zeitpunkt war dieser Wert aktuell?
- Wert: der numerische Wert
Damit kann die Performance und ggf. auch die Anzahl der Fehler oder spezieller Zustände kompakt repräsentiert und z.B. in Grafana grafisch visualisiert werden.
Auf diesen numerischen Werten können Regeln definiert werden, welche eine Aussage liefern, ob das System Grenzwerte überschritten hat – z.B. wenn über 10 Minuten mehr als 90 % der verfügbaren Connections belegt waren oder in 5 Minuten im Durchschnitt mehr als 2 % der Anfragen zu Fehlern führten. Ein Monitoring Tool für Metriken wie Prometheus speichert die Metriken, prüft solche Bedingungen und kann daraufhin die Verantwortlichen darüber informieren.
Unter Monitoring versteht man die Überwachung von Applikation und Infrastruktur. Bei fehlerhaften Zuständen oder Performance-Engpässen werden die zuständigen Betriebsteams benachrichtigt, idealerweise bevor die Nutzer der Applikation größere Probleme feststellen.
State-of-the-art Monitoring-Systeme wie Prometheus sind metrikbasiert. Das heißt, dass sie auf Basis der Metriken Problemzustände ermitteln und Alerts auslösen. Darüber hinaus speichern sie die Metriken über einen längeren Zeitraum, so dass sie über Visualisierungstools wie Grafana auch nachträglich noch zur Analyse von Problemsituationen verwendet werden können.
Eine vergleichsweise junge Disziplin der Observability, welche sich der strukturierten Nachverfolgung auftretender Fehlermeldungen in der beobachteten Software widmet. Auftretende Fehlermeldungen, z.B. in Logs, werden registriert, mit gleichartigen Fehlermeldungen korrelliert (so dass ein 10.000 mal auftretender Fehler nur einen einzelnen Eintrag erzeugt). SRE- und Software-Engineers werden über neu auftretende Fehler automatisch informiert, so dass sie diese gezielt untersuchen und bereinigen können: wesentlich effektiver als das manuelle Durchforsten von gigantischen Anwendungslogs!
In den Myriaden Einzelwerten von Applikations-Metriken versteckt sich so mancher Hinweis auf evtl. problematische Entwicklungen, aber wie findet man diese Nadel im Heuhaufen? Das ist das Anwendungsfeld der Anomaly Detection, eines sehr spannenden Use Cases für Artificial Intelligence (AI). Kurz gesagt lernt ein Anomaly Detection System automatisiert, welche Observability-Daten ein System von sich gibt, wenn es "normal" funktioniert.
Darauf basierend ist es dann in der Lage, Abweichungen von diesem normalen Betrieb (z.B. dramatisch erhöhter Traffic, volllaufende Puffer etc.), ebenso automatisiert zu erkennen und gegebenenfalls zu warnen, obwohl es nie konkret auf die Beobachtung konkreter Metriken programmiert wurde. Dies ist eine sehr hilfreiche Ergänzung zu manuell konfigurierten Alerts um "Blind Spots" in deren Konfiguration zu identifizieren und allgemein auch unvorhergesehene Probleme erkennen zu können.
Aufbau einer komplexen Multi-Site-Observability-Plattform mit VictoriaMetrics, Jaeger und ElasticSearch für Vodafone
Komplexe Anforderungen - ConSol als starker Partner




Noch Fragen zu Observability für businesskritische Anwendungen?

Lassen Sie uns sprechen!
Marc Mühlhoff